




摩登7平台合作客户/
拜耳公司 |
同济大学 |
联合大学 |
美国保洁 |
美国强生 |
瑞士罗氏 |






相关新闻Info
从哪些方面可以体现出酶特异性地结合某种物质?
来源:子薰科学帮 浏览 1508 次 发布时间:2022-06-15
在伽莫夫的设想里,细胞合成蛋白质的场面就像舞会后的姑娘们各自寻找自己的套鞋。氨基酸在双螺旋的小孔上到处试探,最后踩进了最适合自己的孔里,按照DNA上的碱基序列站成了一队。接着,它们只需彼此缩合,就能变成一个大分子的蛋白质了。
那么最妙的部分来了:4种氨基酸分布在前后左右4个方向上,真的刚好形成20种不同形状的孔,与构成蛋白质的20种标准氨基酸在数字上完全匹配!这真是太惊人了,这美妙的契合让伽莫夫如同发现了灰姑娘的王子,迫不及待地把它发表在了1954年的《自然》杂志上,那些设想中的“◆”形状的孔,就因此有了“伽莫夫钻石”这个名字。
结果,在短短几年之内,分子生物学的新发现证明,这套“伽莫夫钻石”美则美矣,实则没有一点儿是正确的。但是,碱基的立体结构与20种氨基酸相互吸引的想法,却并非全无道理,特别是当时的人们正在深入了解酶的催化原理,发现酶总是形成某种特定的三维形状,从而特异性地结合某种物质。
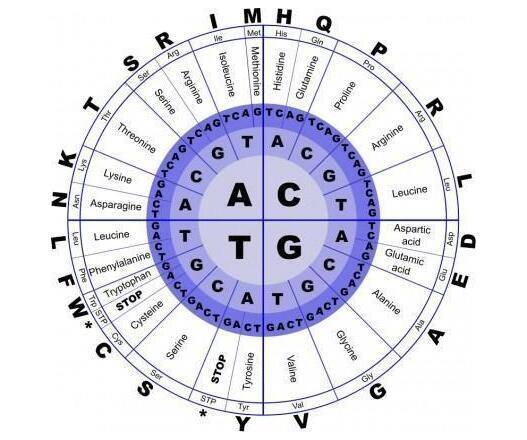
所以标准遗传密码才刚刚破译,基于RNA的立体化学假说就应运而生了。新版本的假说继续猜测RNA密码子上的3个碱基能形成特异的三维结构,能与对应的氨基酸相互吸引,而这种相互吸引就是遗传密码的起源。
在某些实验中,研究者把各种氨基酸与各种碱基序列混合在同一份溶液里,使它们随意组合,结果发现许多氨基酸都与标准密码子有更大的组合概率,这立刻吸引了许多人的目光。然而,遗憾的是,进一步的统计却发现,那种“更大的组合概率”更接近实验不足带来的统计偏差,就如同扔1元硬币连续五次“1”向上,并不代表“1”向上的概率就比“菊花”向上的概率大。
但是总的来说,立体化学假说到目前为止都还缺乏切实的证据支持。稍晚的第二个假说是“错误最小化假说”,故事里多次露面的卡尔·沃斯就是这个假说的重要创建者。
这个假说认为,遗传密码最初在不同的元祖身上形成了许许多多的编码方案,但是不同的方案有着不同的适应性,一个方案把突变造成的错误降得越低,就越能在竞争中胜出,而我们目前的标准遗传密码,就是其中的佼佼者。
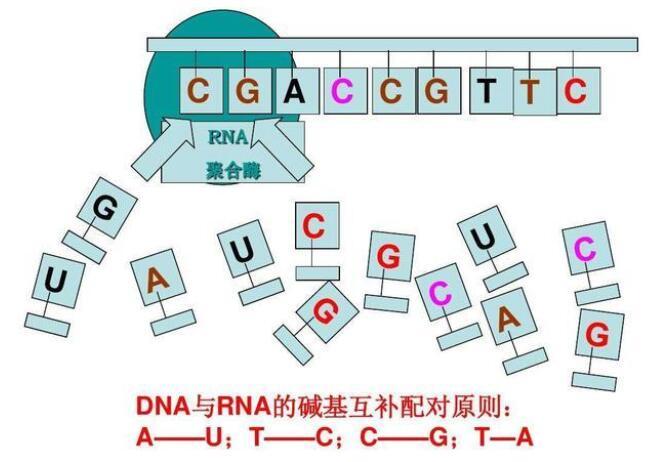
所谓“突变造成的错误”,很好理解:无论DNA还是RNA,它们在任何一次复制、转录或翻译过程中都可能发生碱基突变,一个闪失,C就变成了U,U就变成了A,A就变成了G,这种突变在所难免。
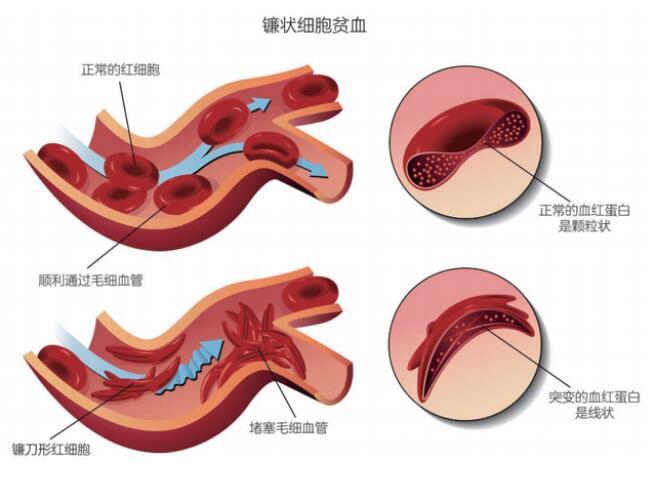
这样的突变一旦发生,这个密码子就变成了那个密码子,如果这两个密码子对应着性质悬殊的两种氨基酸,就很有可能合成出来一个存在严重缺陷的蛋白质。关于这种错误,一个最经典的例子是人类的“镰状细胞贫血”。人体的红细胞里装满了血红蛋白,用来给全身运输氧气。
而镰状细胞贫血,就是患者的血红蛋白基因中有一个A变成了U,把原本编码了谷氨酸的GAG变成了编码缬氨酸的GUG——这就麻烦了:谷氨酸是非常亲水的氨基酸,折叠的时候本来位于蛋白质的表面,帮助血红蛋白溶解在红细胞的细胞质里;缬氨酸却是非常疏水的氨基酸,非常讨厌暴露在水溶液里。
这种突变了的血红蛋白在氧气充裕的时候还好,一旦人体因为剧烈运动或者情绪紧张进入缺氧状态,它们的三维形态就会扭曲起来,然后一个个首尾相接地粘连成一长串。
我们的红细胞原本是中间略扁的圆饼形,这下却被又长又硬的突变血红蛋白凝聚物撑成了镰刀形,不但运输氧气的能力大幅下降,还会卡在毛细血管的拐弯处,形成大范围的栓塞,肝脏、脾脏、红骨髓等毛细血管丰富的组织都将受到严重的损伤。所以,那些从父母双方继承的基因都有这个突变的“纯合”患者,常常会有生命危险。
回到错误最小化假说上,这个假说的研究者用复杂的统计学模型评估了标准遗传密码在一切可能的遗传密码中表现如何,然后发现只有万分之一甚至百万分之一的遗传密码方案能比标准遗传密码更加出色。
我们这套标准遗传密码的突变后果的确是惊人地小,即便一种氨基酸换成了另一种氨基酸,也大多是换成各种性质非常接近的氨基酸,而不给最终的蛋白质带来强烈的影响。尤其显著的是,密码子三位碱基的突变概率并不相等,第二位的突变概率最小,所以我们看到,氨基酸亲水性这个最重要的特征就集中与这一位碱基关联。
这样一来,即便其他两位碱基发生了突变,氨基酸的亲水性也大概没什么变化,最后的蛋白质不至于坏掉。而密码子的第三位那样冗余,则与翻译的细节有关:转运RNA带着氨基酸在信使RNA上匹配密码子并非一蹴而就,是一位一位试探着踩出来的,其中最先试探的就是第三位密码子。
而这贸然的试探出错率非常高,甚至不能保证符合那套“互补配对原则”。这种事情在密码子的第三位上太平常了,只要一个是嘌呤,一个是嘧啶,差不离就能匹配上。所以,密码子的第三位占据的信息量越少越好,能分清嘌呤和嘧啶,也就差不多了。
当然,标准遗传密码虽然很出色,却还不是最出色的,即便人类都能设计出错误影响更小的遗传密码。对此,我们倒不难给出一个非常合理的解释:自然选择从来不追求完美,而只需够用。如果标准遗传密码对突变的抗性已经足够高,那就已经可以保证使用它的细胞不被淘汰,至于那些细胞能不能在竞争中脱颖而出,成为万世的元祖,那要看整个细胞的综合素质,并不只看密码质量一件事。
但是排除了这一点,这个假说也仍然有一些理论上的缺点:它实际上是在解释遗传密码起源之后的早期进化,而不是遗传密码本身的起源,对于密码子第一位碱基的规律,这个假说也缺乏解释力。所以,错误最小化假说目前更多地被看作一个“补充”,而不是真正的“解释”。
20世纪出现的第三种假说,是“协同进化假说”,这个假说并不认为遗传密码从一形成就会被“冻结”,而认为它与生命的一切特征一样,是在进化中变得复杂的。这个假说进一步提出,遗传密码的进化与氨基酸的进化有着紧密的对应关系。
也就是说,最初得到编码的氨基酸并没有20种这么多,而只有区区几种,所以每种氨基酸都对应着许许多多的密码子。而当细胞合成了一种新的氨基酸,就会把某种氨基酸的密码子腾出来一部分,重新分配给这个新的氨基酸。
至于是哪种氨基酸的密码子被腾出来,研究人员推测通常是合成反应类似的氨基酸,尤其是作为新氨基酸原料的氨基酸。第一个系统整理这个假说的,中国一位生物学家,来自香港科技大学的生物化学家王子晖教授。
他在1975年提出的密码子重新分配过程:每一个箭头的两端,都只改变了一个碱基,同时,每一个箭头所指的氨基酸都能由前一种氨基酸合成出来。比如说,王子晖教授推测,最初的谷氨酸不只有今天的GAA和GAG,还占据了CAA和CAG。后来,细胞用谷氨酸改造出了谷氨酰胺,就把这两个密码子重新划给了谷氨酰胺。
再后来,细胞又以谷氨酸为原料合成了精氨酸和脯氨酸,就又把一字之差的CGX碱基全都划分给了精氨酸,CCX碱基全都划给了脯氨酸。就这样,随着细胞的生化反应越来越复杂,密码子的分配也越来越精细。这不但强有力地解释了密码子第一位的规律,而且新分配的密码子当然是不要招致灾祸的好,这又能与错误最小化假说完美地兼容,有效解释了其他两位密码子的规律。
于是,理论与现象的高度吻合让协同进化假说收获了广泛的认可。当然,同之前的三种假说一样,协同进化假说也有自己的缺点:那些箭头代表的并不都是现代细胞真实的生化反应,有许多是推测中的元祖生化反应,而这是存在争议的。
如果把氨基酸当作有机酸的产物,那种关联性也就增强了许多,更何况,那些生化反应虽然存在争议,但元祖与现代细胞有着不同的生化反应,却是完全合理的推测。所以总的来说,协同进化假说是一个非常有希望的假说,将遗传密码的进化与生化反应的进化结合起来,这是高屋建瓴的见解。
时至今日,绝大多数的研究者都认可“遗传密码最初只编码了少数几种氨基酸,然后才在进化中不断扩大到如今的20种”。至于最先得到编码的是哪几种,G开头的4种,即甘氨酸、丙氨酸、天冬氨酸和缬氨酸,又是最被认可的,因为它们的合成反应最简单,而且的确位于密码子扩充路线的起点上。甚至,也有假说认为这4种也有先来后到,结构最简单的甘氨酸曾经独占所有G开头的密码子。